Mỗi biến đầu vào được cung cấp cho mô hình Machine Learning đều được gọi là các Feature Selection – lựa chọn đặc trưng. Mỗi một biến thông tin trong tập dữ liệu đều được tạo thành một Feature (tính năng đặc trưng). Để đào tạo mô hình học máy một cách tốt ưu, chúng ta cần phải chọn đúng các tính năng đặc trưng cần thiết.
Trong bài viết này, chúng tôi sẽ thông tin đến bạn tất cả những điều cần biết về quá trình chọn đúng các tính năng đặc trưng cho mô hình của mình, hay còn gọi là Feature Selection.
Mục lục
Tại sao cần lựa chọn các tính năng (Feature Selection) ?
Các mô hình Machine Learning luôn hoạt động theo một nguyên tắc đơn giản: học từ tất cả các dữ liệu được đưa vào.
Điều này cũng có nghĩa là nếu chúng ta đưa các dữ liệu rác vào để hệ thống học tập, kết quả đầu ra cũng sẽ là rác, không chính xác như chúng ta mong muốn.
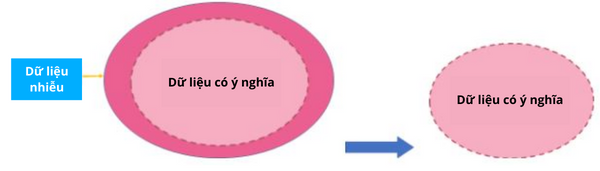
Do đó, để đào tạo một mô hình, chúng ta cần thu thập một lượng lớn dữ liệu có chất lượng để máy tính có thể học hỏi tốt hơn. Thông thường, có 1 phần trong dữ liệu sẽ không có ý nghĩa, không đóng góp quá nhiều vào hiệu suất hoạt động của mô hình Machine Learning. Hơn nữa, việc có quá nhiều dữ liệu có thể làm chậm quá trình đào tạo và khiến mô hình huấn luyện chậm hơn, mô hình cũng có thể học từ các dữ liệu rác này dẫn đến kết quả trả về sau đó không chính xác.

Feature Selection – lựa chọn tính năng đặc trưng là điểm khác biệt khiến một số nhà khoa học dữ liệu giỏi hơn so với số đông còn lại. Với cùng một mô hình huấn luyện và phương tiện, công cụ, tại sao một số nhà khoa học lại xây dựng được các mô hình Machine Learning với tốc độ nhanh hơn và chính xác hơn?
Câu trả lời là nhờ vào Feature Selection. Ngoài việc chọn đúng mô hình phù hợp với dữ liệu đầu vào, chúng ta cũng cần chọn đúng các dữ liệu có ý nghĩa để đưa vào mô hình của mình.
Ví dụ, chúng ta hãy cùng xem xét một bảng thông tin về các xe máy cũ. Mô hình Machine Learning này sẽ học hỏi và chọn ra những chiếc xe sẽ bị tháo gỡ để thay thế phụ tùng, chúng gồm các thông tin sau:
- Mẫu xe
- Năm sản xuất
- Số km đã đi
- Chủ sở hữu
Trong 4 thông tin trên, chúng ta có thể thấy rằng mẫu xe, năm sản xuất, số km đã đi là 3 thông tin quan trọng được dùng để đưa ra lựa chọn có nên tháo gỡ và tiêu hủy xe hay không. Tuy nhiên, về thông tin chủ sở hữu xe thì không liên quan nhiều lắm tới việc có nên tiêu hủy xe hay không. Ngoài ra, chúng cũng có thể khiến hệ thống nhầm lẫn trong việc tìm kiếm sự liên quan giữa các mẫu và tính năng khác.
Do đó, chúng ta có thể bỏ cột thông tin về chủ sở hữu. Đây là lý do chúng ta cần phải thực hiện Feature Selection – lựa chọn tính năng đặc trưng trong mô hình học máy.
Feature Selection là gì?
Vậy, Feature Selection là gì? Feature Selection là một phương pháp giảm số lượng các biến thông tin đầu vào trong mô hình Machine Learning của bạn, bằng cách chỉ sử dụng những dữ liệu liên quan, có ý nghĩa và loại bỏ các dữ liệu nhiễu.
Feature Selection là quá trình tự động chọn các tính năng liên quan đến mô hình học máy của bạn, dựa trên vấn đề mà bạn cần giải quyết.
Chúng ta thực hiện công việc này bằng cách gom lại hoặc loại trừ các tính năng không ảnh hưởng đến kết quả đầu ra. Điều này giúp giảm dữ liệu nhiễu và giảm lượng dữ liệu đưa vào ban đầu.
Các mô hình Feature Selection
Có 2 loại mô hình chính:
- Mô hình được giám sát: Sử dụng lớp nhãn đầu ra để lựa chọn đối tượng. Hệ thống này sử dụng các biến mục tiêu để chọn ra các biến có thể tăng tính hiệu quả cho mô hình
- Mô hình không giám sát: Không cần lớp nhãn đầu ra để lựa chọn đối tượng.
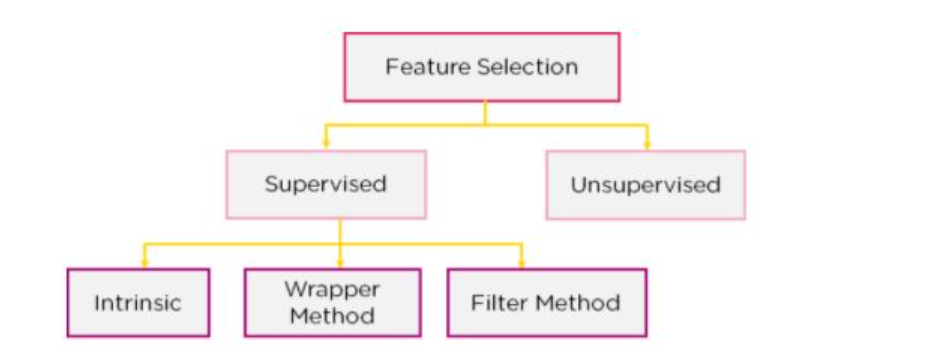
Với mô hình được giám sát, chúng ta có thể chia thành 3 mô hình nhỏ nữa:
- Bộ lọc (Filter Method): Trong phương pháp này, các tính năng bị loại bỏ dựa trên mối quan hệ của chúng với đầu ra, hay nói cách khác là cách chúng tương quan với đầu ra. Chúng ta sẽ xem xét các tính năng đặc trưng đó có tương quan tích cực hay tiêu cực với các nhãn đầu ra không, sau đó loại bỏ các tính năng không phù hợp.
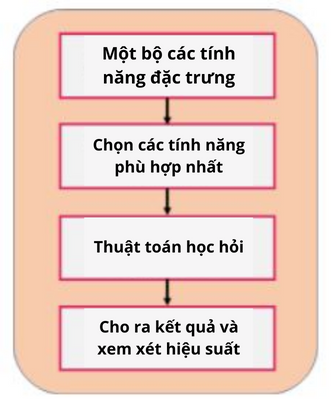
- Phương pháp Wrapper: Chúng ta sẽ chia dữ liệu thành các tập hợp con và huấn luyện hệ thống Machine Learning. Dựa trên kết quả đầu ra của mô hình, chúng ta sẽ thêm và bớt các tính năng, sau đó huấn luyện lại mô hình.
Mô hình này sẽ tạo thành nhiều tập hợp con, bằng cách đánh giá độ chính xác cũng như hiệu suất của tất cả các bộ tổ hợp tính năng khác nhau có thể xuất hiện.
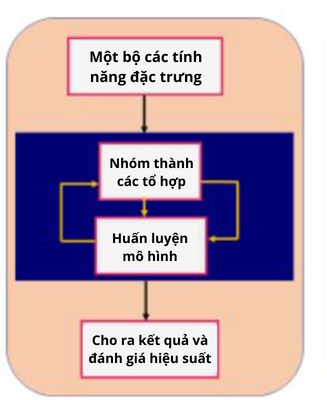
- Phương pháp Intrinsic: Là phương pháp kết hợp cả 2 phương pháp nêu trên để tạo thành một tập hợp các tính năng đặc trưng tốt nhất.
Phương pháp này sẽ huấn luyện hệ thống liên tục, lặp đi lặp lại mãi trong khi vẫn duy trì chi phí tính toán ở mức thấp nhất có thể.
Lời kết
Trên đây là các thông tin chính về Feature Selection cũng như các phương pháp chọn tính năng đặc trưng phù hợp cho mô hình Machine Learning của bạn.
Đây là 1 trong những bài viết thuộc chuỗi bài về hướng dẫn AI & Machine Learning của chúng tôi, bạn hãy truy cập toàn bộ chuỗi bài viết để tìm hiểu kỹ hơn về chủ đề này nhé!
Nếu bạn có bất kỳ thắc mắc nào khác, vui lòng liên hệ chúng tôi để được hỗ trợ.
Để tìm hiểu thêm về kit học STEM và các chương trình dạy học STEM, vui lòng liên hệ OhStem qua:
- Fanpage: https://www.facebook.com/ohstem.aitt
- Hotline: 08.6666.8168
- Youtube: https://www.youtube.com/c/ohstem
OhStem Education – Đơn vị cung cấp công cụ và giải pháp giáo dục STEAM cho mọi lứa tuổi tại Việt Nam









